CHAPTER NINE
Direct Inference
Hitherto our method of proving the validity of implications has been 'through the impossible' as Aristotle would say. Assume the contrary, if this leads to impossibility (the mark!), then the assertion to be proved must be true after all. When an implication is to be proved, the contrary assertion - more precisely the negation or contradiction - is that the (very likely compound) premise P is true and the conclusion C is false. All our efforts have been directed to the task of proving equivalences of the type
P ∧ ¬C = False [in all models],
and we have discovered (Theorem 8.5) that this is equivalent to the task of proving
Q D* ≅ O ,
where Q and D* are CLS-expressions, such that Q is the transcription of the wff P, and D* is the transcription of the wff ¬C; and ≅ denotes CLS-equivalence.
To get an idea of what we might mean by positive or direct inference, let us return to a simple example given in Chapter One (Example 1.3). We found (with some changes of letters, and order)
(Rxy(Ryx)) Rab » Rba .
(Recall that » denotes CLS-dominance; for the definition see Definition 1.4.) Now the first factor on the left is clearly the transcription of the wff
∀x∀y (Rxy → Ryx),
which tells us that R.. is a reflexive relation: if any x stands in the relation R to any y, then y stands in the same relation to x. The second factor is the transcription of itself: it tells us that the constants or particular individuals a and b are such that a stands in the relation R to b. And the factor on the right of the dominance sign transcribes the assertion that b stands in the relation R to a.
Now, it is obvious that the premise 'R is reflexive, and Rab' does in fact imply the conclusion Rba. But does the fact that
(Rxy(Ryx)) Rab » Rba .
constitute a proof of the implication?
Well, it's only one step away from a proof, because we can add in the expression (Rba) to both sides of the dominance relation to obtain:
(Rxy(Ryx)) Rab (Rba)» Rba (Rba) = O.
Here the expression on the far left transcribes the assertion 'R is reflexive, Rab and not-Rba'; and this expression is shown to be mark-equivalent. Therefore, by Theorem 8.5, the implication is valid.
But can this approach be generalized? If Q transcribes P, and D transcribes C and
Q » D ,
can we take this as proof that P implies C?
If the transcription of ¬C were simply (D) - that is, D with a circle round it - we would have plain sailing. For
Q » D
implies (using Lemma 1.5)
Q (D) » D (D) = O
which would prove that P implied C by Theorem 8.5.
But in general the transcription of ¬C will not simply be (D); it will be, rather, a different expression which we will call D*. The difference arises when C contains quantifiers. In the course of the transcription process, these get replaced by Π-operators, which then get eliminated by Skolemization. But this is where the crucial difference between C and ¬C comes in: the extra not-circle around ¬C means that the variables which get Skolemized (or replaced by constants) in C are precisely those which do not get Skolemized in ¬C, but which are the contrary retained as 'free variables'. (We will investigate all this in more detail a bit later.)
Fortunately, this setback - the fact that D* is not the same as (D) - turns out to be no more than a hiccough, not a disaster, as will be seen in the proof of the following
Theorem 9.1 Direct Inference
Suppose P and C are wffs, and Q, D are CLS-expressions, such that Q transcribes P and D transcribes C; and suppose further that
Q » D ;
then P → C is a valid implication.
Proof
Let D* be the transcription of ¬C. Now, the assertion C ∧ ¬C is false in all models (it is unsatisfiable). For whatever value C takes, ¬C takes the opposite value. But the transcription of this assertion is D D*, so by Theorem 8.5 we have
D D* ≅ O .
From the premise
Q » D ,
we may deduce (again using Lemma 1.5)
Q D* » D D* ≅ O.
Therefore Q D* is mark-equivalent, and, by Theorem 8.5, P → C is true in all models ◊
Remark 9.2
The theorem gives us the sense in which it may be said that the rules of dominance in the CLS-calculus are interpretable as the rules of deduction in Predicate Logic.
Remark 9.3
It is of interest, perhaps, to see directly that D D* must be mark-equivalent. Suppose C has got to the stage in its transcription when all occurrences of ∀ and ∃ have been replaced by Π-operators. Then, at the same stage, ¬C will transcribe to exactly the same expression but with an extra circle round it. Schematically, the two expresions will look something like this. We say schematically, because we have left out all the atomic formulae, leaving only the Π-operators. The invisible atomic formulae are however exactly the same in both expressions.
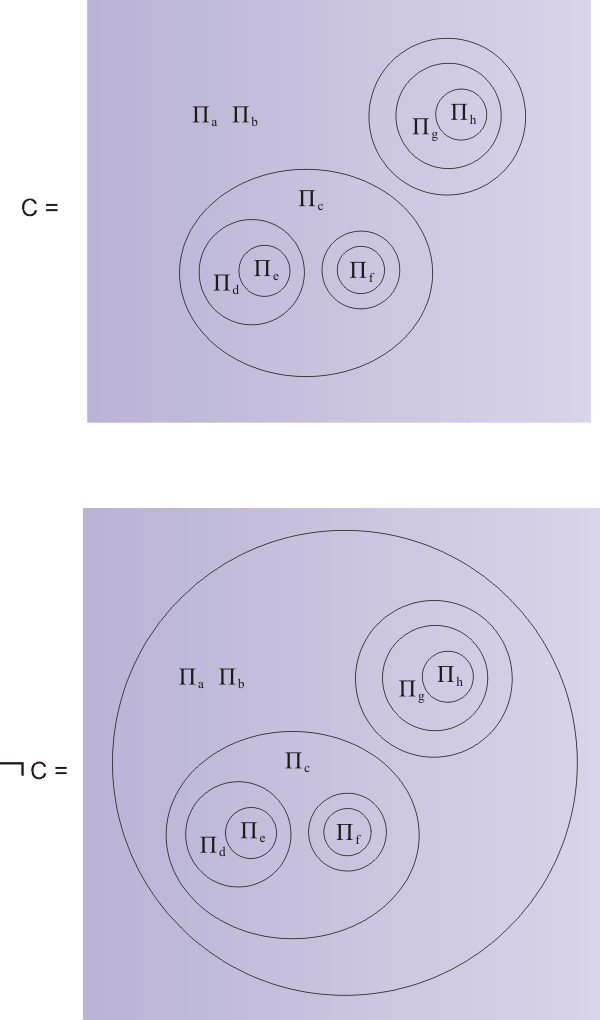
However, the extra circle around the outside of ¬C makes all the difference when it comes to skolemization. For in any expression it is the variables at odd levels (depth -1, -3, -5 etc.) that end up skolemized or turned into constants. The extra circle round the outside has the effect of turning all the odd levels into even ones and vice versa. So the variables that get skolemized in the expression C are precisely those that do not get skolemized, but remain as variables in the expression ¬C.
Concentrating on C for a moment, we can represent the skeleton of the expression by a tree - see the left-hand part of the figure below. (Here the spaces are represented by the nodes, the circles by the lines between nodes. The number of spaces is always one more than the number of lines.) In the right-hand part we have added letters to the nodes, representing the Pi-operators that are located in the corresponding spaces.
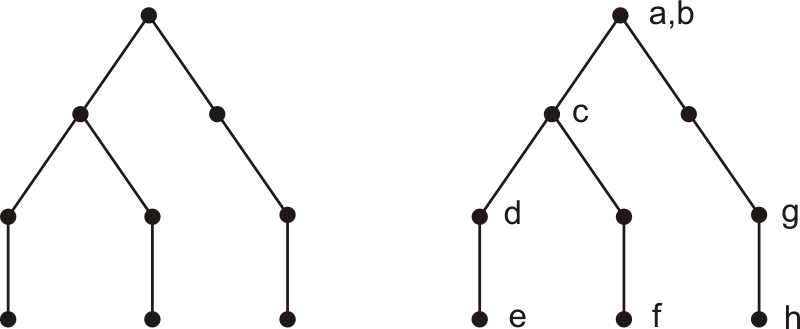
This is how the skolemization goes: a and b are top level, so left alone; then
c → cab
with subscripts because of the Pi-operators in the outer space. Then d can move up to the top level, e to level -1, where it is skolemized, with a, b and d as subscripts:
e → eabd .
On the other branch, variable f is skolemized, with dependence on a and b, but not d (as that belongs to a different branch):
f → fab .
Finally,
h → habg .
The remaining variables, a, b, d and g are left as variables/mutables. Now let's see what happens with ¬C. Now the tree looks like this:
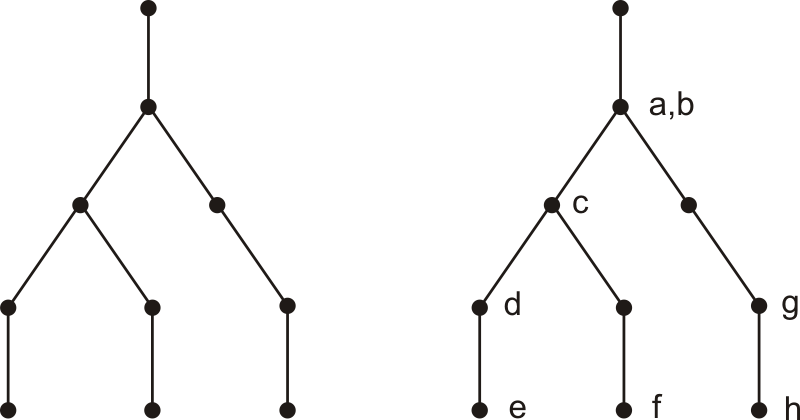
Variables a and b are now at level -1, so require skolemization:
a → a
b → b .
c remains as a variable. At level -3:
d → dc
g → g ;
while at level -4, e, f and h remain as variables.
Now consider the CLS-expressions D and D*. These will have the same atoms in the corresponding places in the skeleton, except that their subscripts will have been changed differently by the process of skolemization. However, the subscripts are capable of being made one again by the process of Unification. We are going to construct a substitution θ such that
D*θ = ( Dθ ) ;
which will have as a consequence
{ D D* }θ = Dθ D*θ = Dθ ( Dθ ) = O ,
implying
D D* ≅ O .
These are the successive steps by which the unifying substitution is constructed:
a → a
b → b
c → cab
d → dcab
e → eabdcab
f → fab
g → g
h → habg
The details hardly matter: the main thing is the fact that (D) and D* can be fully unified, which leads directly to the mark-equivalence of D D*. It is left to the reader to satisfy him or herself that the possibility of unification does not depend on the particular form of expression chosen for this demonstration, but will apply to all such expressions D and D*, arising from logical formulae C and ¬C ◊